Handling language stack deprecations: Part 2: Container infrastructure
15 Jun 2021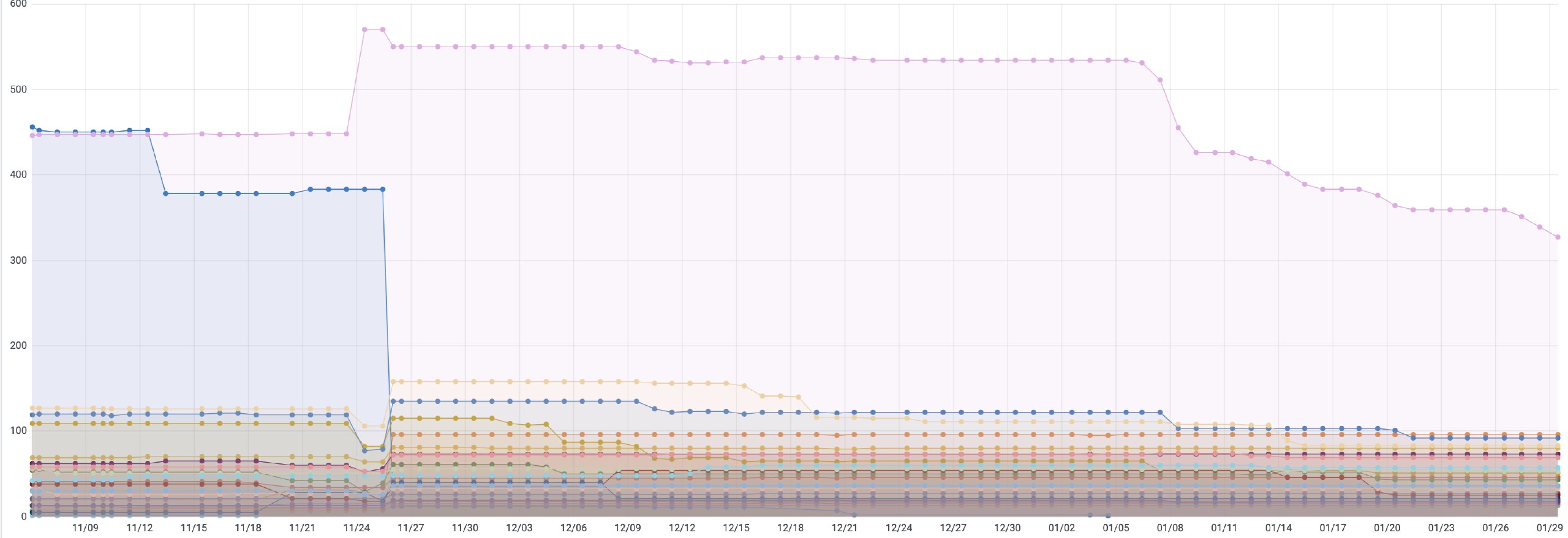
Given the number of language stacks which different product teams end up using inside the org, variations come, in the form of different versions being used, or different versions of dependent libraries coming in. This combination will quickly lead up to a whole set of container image variations for a particular language, crossed with operating system versions.
What is the problem then?
Tracking what is being used by different product teams and their services arises when we would want to know what infrastructure combination is being used by different services. Tracking this piece of information is paramount for a couple of reasons for the central infrastructure team.
If you don’t know what people run, you wouldn’t know what to deprecate. Or in other words. You wouldn’t know what you support for the product teams.
Upgrades/Deprecations
For example, Ubuntu 16.04 LTS recently got EOL’d, back in April 30th, 2021 where-in it stopped receiving security updates, creating an invetory of which services, in case they are using deprecated OS versions for example, would help in prioritizing and notifying the product teams about the impending upgrade.
This applies very well to the language stack deprecations needing to be done.
Library additions
Catering to different requirements of library versions and variations of libraries required by each language+os stack variation also crops up. Deprecating/upgrading existing versions would need tracking as a pre-requisite.
What did we end up doing
Given this would need to be solved for all applications inside the org, we started to tackle the problem starting with tracking the container images being used by the services onboarded to our internal service registry, to begin with and then handle the services which were not onboarded to the service registry.
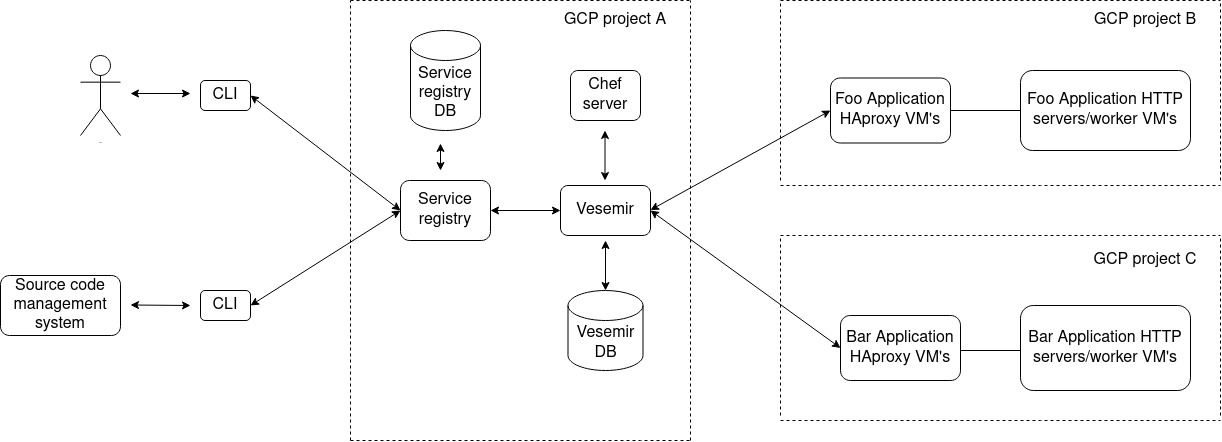
Given our deployment flow, the cli which we give out to the developers, is the first touchpoint in the CI/CD pipeline. The container images to be used for packaging and deploying the application are specified in the CI/CD pipeline configurations. Now we would want to parse this information present already by one of the scripts being used to either deploy/build/run test stage.
Given the simplicity of the solution, it would be simpler to just parse that specific string line for the container images for packaging the application and the image which is being used as the base image.
The deploy scripts are just a wrapper which make use of the cli interacting with the central service registry to deploy the application, along with added logic to handle the response
Next was to just add a simple route on the service registry which would recieve an HTTP request to receive this information, everytime a deployment would happen via the CI/CD UI. Leading to updation of this information for each application.
Current state
As of now this script of fetching this information is run for each and every k8s deployment which we run via our deployment automation.
This has in turn helped us create the inventory of all the language stacks which are actually being used by the applications which are onboarded to our internal service registry and having deployments orchestrated via the same to our k8s clusters.
For deployments happening via other automation tools (helm for eg), we currently don’t have support to fetch what is the language stack being used.
Challenges faced
- There were places where we wouldn’t be able to gauge the language stack version from the env vars which we would parse for an application, as there would be multiple versions present of that env var which were declared. We didn’t want to handle such cases initially, as we wanted to first cover the ideal cases first. Leaving this as an anamoly
- Some applications hadn’t been deployed since months/years. Asking the devs to deploy was one solution, but there were cases where the services had no clear ownership, we didn’t want to deploy the application, to just fetch this information. We ended up creating an automation where we would fetch such applications from the source repository, running the parse logic and then making the http call to the service registry to store the information.
The solution was not perfect, but this worked for us to build the initial language stack inventory for containers.
The next thing which we did was to plot this information on grafana to be easily accesible.
Future
We would want to then onboard our other applications which are not present in the service registry, to track their stack versions. Which would allow us to have more coverage on what are we currently supporting for the org, which would be the next step.
Takeaways
- If we don’t know what we are running, we will not know what are we supporting
- This becomes paramount, whenever we are trying to resolve security issues/add patches to software/support existing software
- Not having this information would mean, getting surprised about the issues which come along with the versions of stacks which you are not aware of.
- Piggybacking on existing workflows helped expedite the whole process of fetching the language stack information for an application
If you liked what you read here, I have written a bit more about how we did the same for virtual machines here