Self hosting kubernetes
04 Apr 2019 #kubernetes #aws
kubernetes has been around for some time now. At the time of writing this article, v1.14.0 is the latest release and with each new release, they have a bunch of new features.
This post is about the initial setup for getting the kubernetes cluster up and running and assumes that you are already familiar with what kubernetes is and a rough idea on what the control plane components are and what do they do. I gave a talk on the same subject of self-hosting kubernetes in DevOpsDays India, 2018
You can find the slides of the talk above.
Although there are other tools like kubeadm which would help you to self-host kubernetes, I would like to show how bootkube does it.
What is self-hosting kubernetes?
It runs all required and optional components of a Kubernetes cluster on top of Kubernetes itself. The kubelet manages itself or is managed by the system init and all the Kubernetes components can be managed by using Kubernetes APIs.
source: CoreOS tectonic docs
In a nutshell, static Kubernetes runs control plane components as systemd services on the host. Its simple to reason about and the repo has educational docs, but in practice, it’s fairly static (hard to re-configure). Self-hosted Kubernetes runs control plane components as pods. A one-time bootstrapping process is done to set up that control plane. Configuring hosts becomes much more minimal, requiring only a running Kubelet. This favours performing rolling upgrades through Kubernetes, the cluster system, and provisioning immutable host infrastructure. A node’s only job is to be a “dumb” member of the larger cluster.
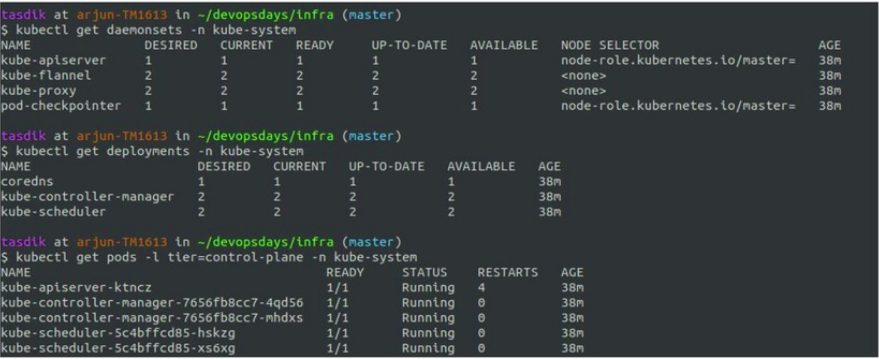
The cluster which you see above is a self-hosted cluster, hosted on digitalocean using typhoon. For reference, you can check the terraform config to bring up your own cluster using typhoon.
What you can see above is how you can use kubectl to interact with the different components of the kubernetes cluster and how they are abstracted in terms of the native kubernetes objects like deployments, daemonset
Is this something new?
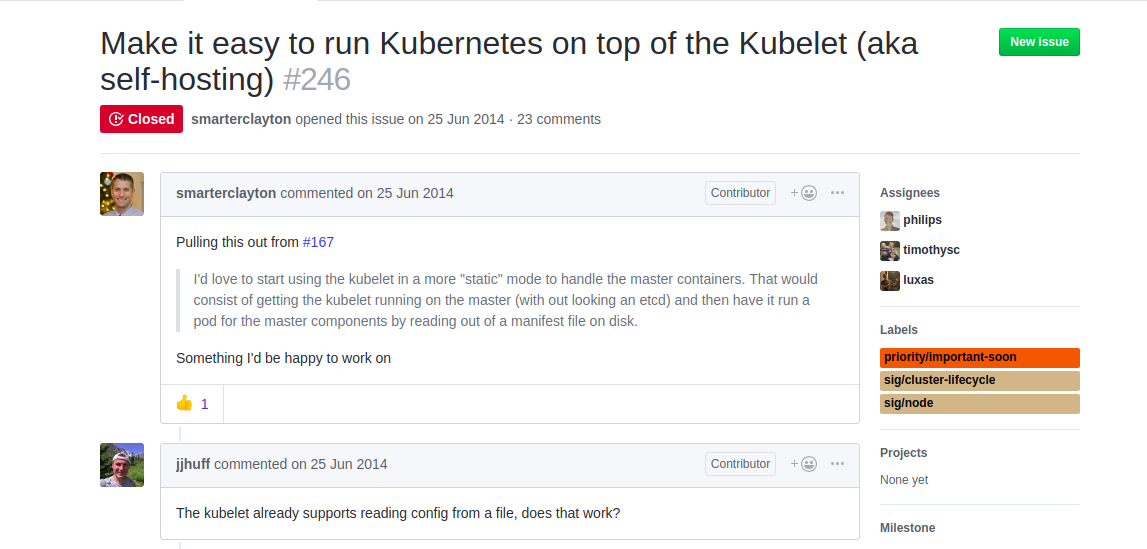
This has been in discussion for quite some time and a lot of people have already done it in production
Why?
What are the usual properties of the k8s control plane objects.
- Highly available
- Should be able to tolerate node failures
- Scale up and down with requirements
- Rollback and upgrades
- Monitoring and alerting
- Resource allocation
- RBAC
How is self-hosted kubernetes addressing them
- Small Dependencies: self-hosted should reduce the number of components required, on the host, for a Kubernetes cluster to be deployed to a Kubelet. This should greatly simplify the perceived complexity of Kubernetes installation.
- Deployment consistency: self-hosted reduces the number of files that are written to disk or managed via configuration management or manual installation via SSH. Our hope is to reduce the number of moving parts relying on the host OS to make deployments consistent in all environments.
- Introspection: internal components can be debugged and inspected by users using existing Kubernetes APIs like kubectl logs
- Cluster Upgrades: Related to introspection the components of a Kubernetes cluster are now subject to control via Kubernetes APIs. Upgrades of Kubelet’s are possible via new daemon sets, API servers can be upgraded using daemon sets and potentially deployments in the future, and flags of add-ons can be changed by updating deployments, etc
- Easier Highly-Available Configurations: Using Kubernetes APIs will make it easier to scale up and monitor an HA environment without complex external tooling. Because of the complexity of these configurations tools that create them without self-hosted often implement significant complex logic.
- Streamlined, cluster lifecycle management: you can manage things using your favourite tool like kubectl
Let’s try explaining the above one at a time.
Small dependencies

- Forget about masters for a second, for worker nodes, the components above is all you need for it to connect to the cluster.
- Everything is running inside kubernetes.
- Master nodes might have systemd units and some other specialised scripts to run.
- There is no distinction between the nodes.

The nodes are only differentiated on the basis of k8s labels which are attached to nodes and are the only way one can distinguish between the master the other kinds of nodes.
This is done in order so that the scheduler can schedule only the required workloads on the nodes of a particular kind, for example. The API server should only be running on the master nodes, and hence it will try using the label which is attached to the master nodes, tolerate the taint and get scheduled on the master nodes.
Adding labels to a node is as simple as doing a
$ kubectl label node node1 master=true
Introspection
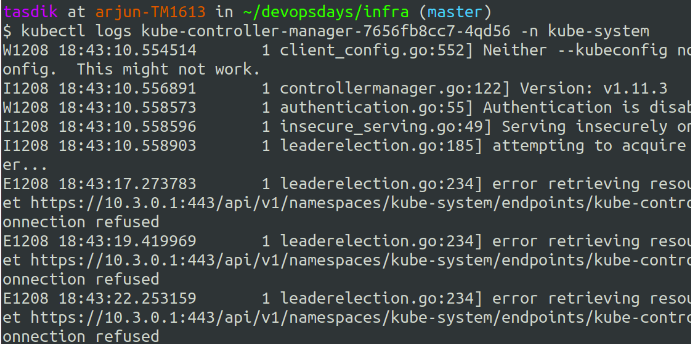
All the control plane objects run as one or the other kubernetes objects, what happens then is you get the power of doing something like kubectl logs .. on the particular object to get the logs.
You can go ahead and send these logs to your logging platform just like how you would do to your application logs. Making them searchable and gaining more visibility on the control plane objects.
Cluster Upgrades

Doing a cluster upgrade for a particular component is as simple as doing a kubectl set-image on the particular control plane object.
First comes the API server. A certain flow needs to be replicated while doing upgrades, but other than that. This is really just it for upgrades
Easier highly available configurations
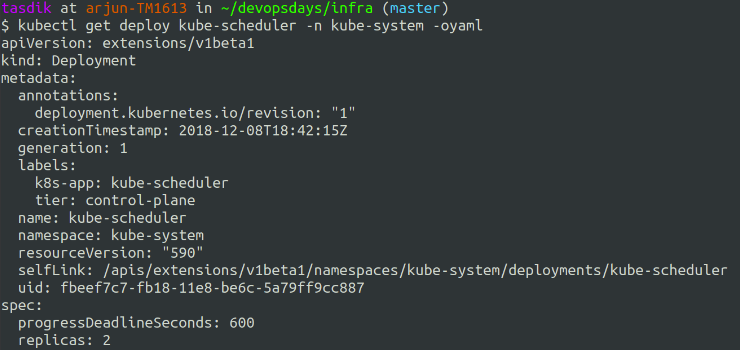
As the core control plane objects are running as kubernetes objects like deployments, you can increase their replica count and make it scale up/down to the desired number which you would want.
Wouldn’t really affect the scheduler/controller-manager/api operations too much if you are thinking of scaling them up and expecting performance improvement as each of them take a lock on etcd and elect a leader, hence only one of them is active at any given point.
Streamlined cluster lifecycle management
Like any of your apps, your control plane objects can be applied to your cluster in a similar way.
$ kubectl apply -f kube-apiserver.yaml
$ kubectl apply -f controller-manager.yaml
$ kubectl apply -f flannel.yaml
$ kubectl apply -f my-app.yaml
Which gives you a familiar ground to be in, of course, you should try not doing the above in prod and have some kind of automation to do things instead of doing kubectl apply.
How does all this work?
There are three main problems to solve here

Bootstrapping
- Control plane running as daemonsets, deployments. Making use of secrets and configmaps
- But … We need a control to plane to apply these deployments and daemonsets on

How to solve this?
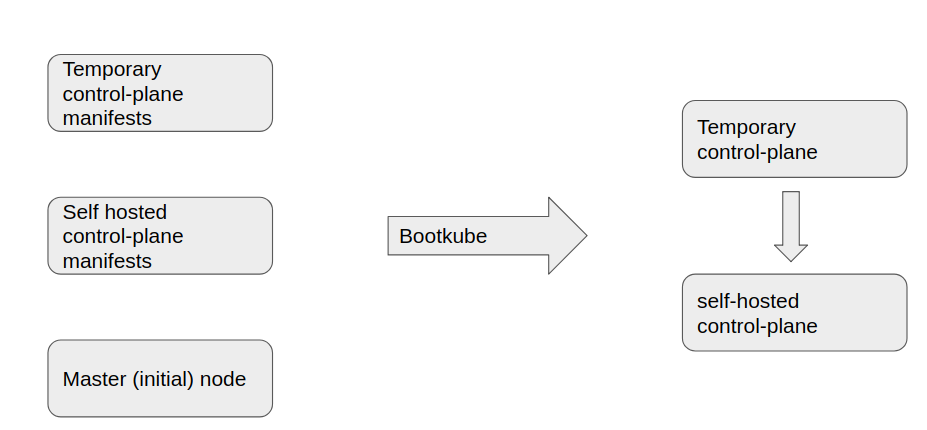
Bootkube can be used to create the temporary control plane which can be then used to inject the control plane objects.
How does bootkube work?
A very rough way of describing the set of operations
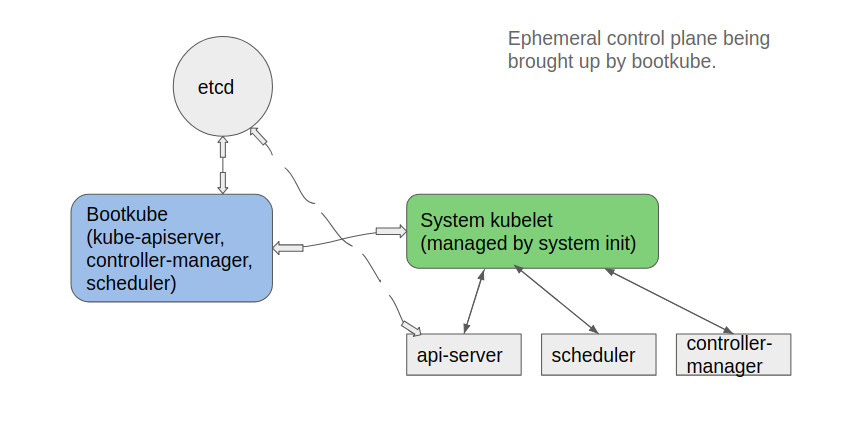
- Bootkube starts, and drops api-server, scheduler, controller-manager, and etcd pod manifests into:
/etc/kubernetes/manifests. - This static (and temporary) control-plane starts, then bootkube injects daemonsets, deployments, secrets, & configMaps which make up the self-hosted control-plane.
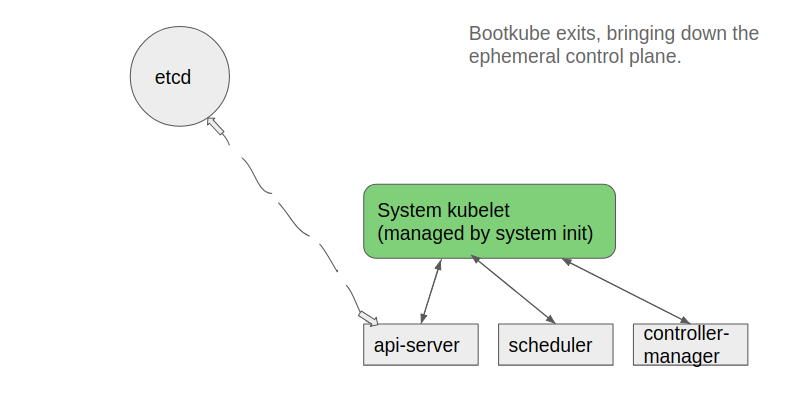
- Bootkube waits for the self-hosted control-plane to start, and when all required pods are running, bootkube deletes the static manifests in
/etc/kubernetes/manifestsand exits (leaving us with a self-hosted cluster)
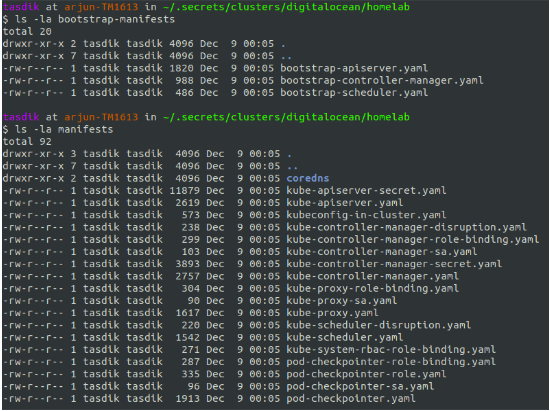
So you have manifests in two directories
bootstrap-manifests
which would hold the temporary control plane manifests, which bootkube would bring up
manifests
which would be the manifests applied, when the API server pivots from the temporary one to the one which was injected and applied when bootkube exited.
Does this even work?
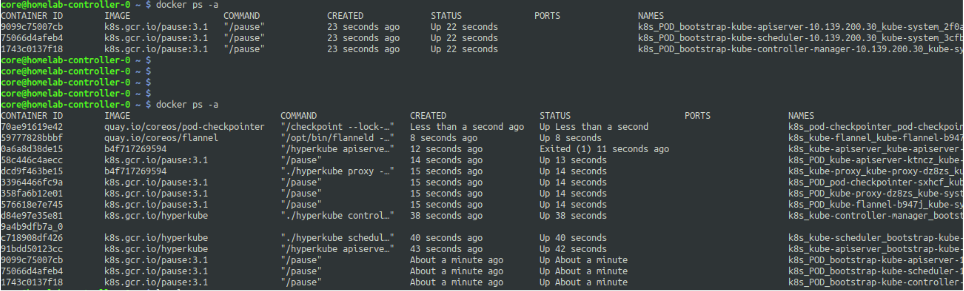
What you see above are the logs of a controller node when the cluster is brought up. The initial docker ps -a would show the bootstrap control plane objects which were brought up bootkube.
The second docker ps -a shows the list of containers which are part of the pods when all the other manifests in the manifests dir got applied.
Tools to self host k8s clusters
Although I have used typhoon to bring up my kubernetes clusters, check out gardener cloud which can also help you achieve self hosted kubernetes.