Extraction of text from image using tesseract-ocr engine
04 Apr 2016
This post was long overdue!
We have been working on building a food recommendation system for some time and this phase involved getting the menu items from the menu images
We poured over at zomato’s site looking for menu’s and all we found was images in the name of menu’s

This is not what we wanted!
We want the menu items tp be in text format, so that we can easily track which restaurants are serving which dish and analyze the reviews to see which restaurant serves best
Scrape them all!
The first step was to scrape the images of the hotels.
The very first apps which came to our mind when we thought about food were no other than zomato and burrp (brownie points for those for whom these were the names echoing in their minds).
Zomato kept blocking our crawlers from time to time. So we found burrp to be a boon in this sense.
You can find some of the webscrapers here (https://github.com/foodoh/web_scrapers)
Enter OCR
So the obvious choice was to apply image processing techniques so as to extract the text inside these images
We thought we would be getting okayish results using the tesseract-ocr engine for this purpose. If you haven’t heard about it. tesseract is maitained by google and provides a decent API for getting the job done!
We ran some of our images on it wihout any pre-processing and waited for the result. But we were in for a rude shock. Not only were we getting bad results but some of them were outright garbage text
Tell me if you can comprehend any of this
M hm mkflfiffi {MWfl m lax-g;
lug-BI I 1. I I.“ n I
III"- - ‘I I Mb. I I
I‘M“ - ‘I I “IQ-h I .
in“ . 1. I “my I I
III-“mun. - 1I I I‘M n I
lOl-I I I Ila-Inn." P! I
Imus-n I Ia—l— I I
'wm ll Intimi— I I
mm lulu - I III-m - I
'60.“ II I II._~ . o.
'm“ : Iain—Lita 1| I III—I.— - .-
uhfinI—II I . I I w“ n I
nun—n.- . "h." III-nun— a I
m um:
I n
H .
C -
I I
I n
C I
I 1!
This is supposed to be the text list of menu items extraced from this image

Sucks right?
But some results were turning out fine. Take for instance this image (link)
{kind=link}
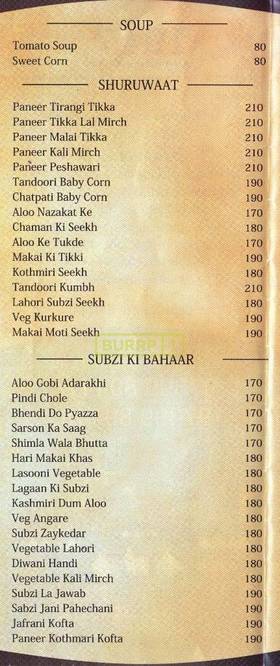
Result for this (link)
777 fl
SOUP
Tomato Soup 80
Sweet Corn so
SHURUWAAT
Paneer Tirang! Tikka 210
Paneer Tikka La] Mirch 2 w
Paneer Malai Tikka 210
Paneer Kali Mirch 210
Pafieer Peshawari 210
Tandoori Baby Corn 190
Chalpali Baby Corn 190
Alan Nazakat Ke 170
Chaman Kl Seekh 180
A100 Ke Tukde 17o:
Makai Ki mm 190
Kuuiiniri Seekh lao
Tandoori Kumbh 2w
Lahnri Suhzi Seekh 180
Veg Kui-kurc 190
Makai Maxi Scckh 190
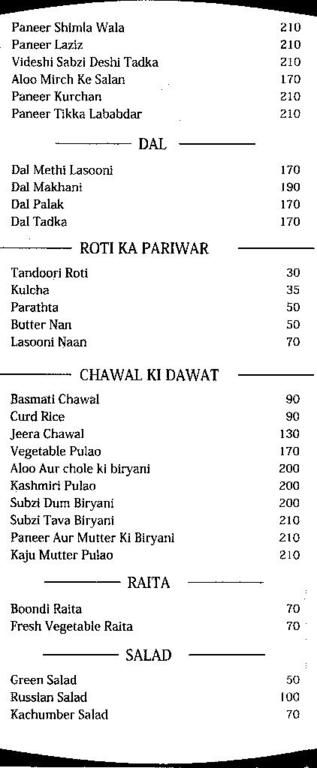
— SUBZI KI BAHAAR
A100 Gobi Adarakhi 170
Pindi Choic 11o
Bhendi Do Pyazza 170
Sarson Ka Saag 170
Shin-i121 W313 Emma 170
Had Makai Khas 180
Lasnoni Vegeiahle 180
Lagaan Ki Subzi 180
Kashmiri Dum A100 180
Veg Angare 180
Subzi Zaykcdar 180
Vegomble Lahari 12m
Diwan] Handi 130
Vegetable Kali Mirch 180
Suhzi La Jawab 190
Sahzi Jam Pahechani 190
Jafrani Kufta 190
Panzer Knthmari Kufia 190
Decent enough for me.
Grayscaling the images
Now after some reading, we found out that grayscaling the images according would increase the OCR accuracy.
A simple PIL program for that
This improved the accuracy to a certain extent. Here is a sample greyscaled image for you (link)
{kind=link}
Some of the cleaning scripts lie here (https://github.com/foodoh/image_cleansing/)
Automating the task of OCR
Now tesseract was provinding a CLI interface for interacting with it. But how would you automate this? I am not gonna sit there and type
$ tesseract myscan.png out
for each and every image scraped!
Enter python!
As always. python comes to the rescue. I wrote a simple script which ran over the image directories, looping over each and every image for each hotel and ran tesseract-ocr on them.
Storing of each hotel’s text menu was done in a different file with the name that file being the hotel’s normalized name.
You can find most of the scripts used for this automation here
Stay tuned for more!