Making of Trumporate: Building markovipy - Part 1
06 May 2017 #python
Do you even read comics?
Kiddin. Between, I love reading Calvin and Hobbes. It’s something which I keep re-reading their well worn collections, maybe for the n-th time. The thing which keeps me hooked to it maybe the blunt truthfulness of strip.
Haven’t read any?
I like this one because of its simplicity.

This one makes me smile all the time.

xkcd is the only thing that comes close in comic strips which I visit frequently.
Psst. Let me tell you something
The picture which you saw, titled is “calvin and Markov”, is generated using Markov Chains as explained here by the author. So it’s not written by a human but generated programmitcally using a corpus.
Markov What?
Quite simply put, it theorises that
every event happening is dependent on its previous event that occurred.
When the probability of some event is dependent or is conditional on previous events, we say they are dependent events.
Let me put it this way.
You could relate to it from the fact that most of the things in the physical world are dependent on their previous outcomes.
Imagine a coin flip, which is dependent on previous outcomes. So it has short-term memory of one event. This can be visualised using a hypothetical machine which contains two cups, which we call states. In one state we have a 50-50 mix of light versus dark beads, while in the other state we have more dark versus light. One cup we can call state zero.
It represents a dark having previously occurred, and the other state, we can call one, it represents a light bead having previously occurred. To run our machine, we simply start in a random state and make a selection. Then we move to either state zero or one, depending on that event. Based on the outcome of that selection, we output either a zero if it’s dark, or a one if it’s light.
With this two-state machine, we can identify four possible transitions. If we are in state zero and a black occurs, we loop back to the same state and select again. If a light bead is selected, we jump over to state one, which can also loop back on itself, or jump back to state zero if a dark is chosen. The probability of a light versus dark selection is clearly not independent here, since it depends on the previous outcome.
But Markov proved that as long as every state in the machine is reachable, when you run these machines in a sequence, they reach equilibrium. That is, no matter where you start, once you begin the sequence, the number of times you visit each state converges to some specific ratio, or a probability.
Quite naturally , if it rains when it’s a cloudy day. You don’t drown when you are in your bed.
This helps in calculating the conditional probability and can be applied to various scenarios.

Why am I so interested in it?
Maybe because it comes into the intersection of math and linguistics. Or maybe I wanted something new to fool around. Take your pick. You wouldn’t be wrong both ways.
Going down the rabbit hole I wanted to build something of my own with this new found knowledge from the read ups.
I built Markovipy, a Markov Text Generator which can be used to randomly generate (somewhat) realistic sentences, using words from a source text. Words are joined together in sequence, with each new word being selected based on how often it follows the previous word in the source document.
The results are often just nonsense, but at times can be strangely poetic - the sentences below were generated from the text of “The Hamlet” by Shakespeare:
If his occulted guilt, Do not it selfe vnkennell in one speech, It is most retrograde to our desire And we beseech you, bend you to remaine Heere in the cheere and comfort of our eye, Our cheefest Courtier Cosin, and our whole Kingdome To be contracted in one brow of woe Yet so farre hath Discretion fought with Nature, That we with wisest sorrow thinke on him, Together with remembrance of our selues.
Here I was using a chain length of 3 which optionally represents the number of words taken into account when choosing the next word. Chain length defaults to 1 (which is fastest), but increasing this may generate more realistic text, albeit slightly more slowly.
Depending on the text, increasing the chain length past 6 or 7 words probably won’t do much good – at that point you’re usually plucking out whole sentences anyway, so using a Markov model is kind of redundant.
I got them off Project Gutenberg. The usual copyright headers had to be removed so that they could serve as useful sample input, but naturally all the rights and restrictions of a Gutenberg book still apply.
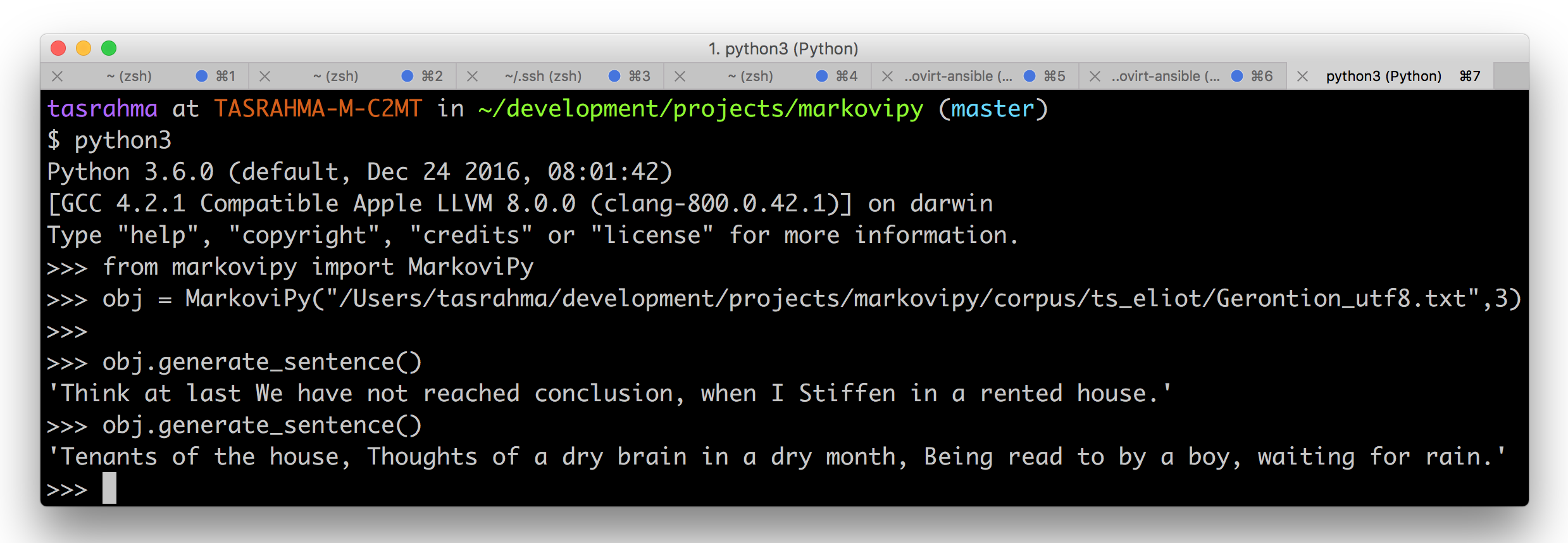
The API looks something like this
>>>
>>> from markovipy.markovipy import MarkoviPy
>>>
>>> obj = MarkoviPy("/Users/tasrahma/development/projects/markovipy/corpus/shakespeare/hamlet_utf8.txt", 3)
>>> obj.generate_sentence()
'If his occulted guilt, Do not it selfe vnkennell in one speech, It is most retrograde to our desire And we beseech you, bend you to remaine Heere in the cheere and comfort of our eye, Our cheefest Courtier Cosin, and our whole Kingdome To be contracted in one brow of woe Yet so farre hath Discretion fought with Nature, That we with wisest sorrow thinke on him, Together with remembrance of our selues.'
>>> obj.generate_sentence()
'Fare you well my Lord Ham.'
>>> obj.generate_sentence()
'To thinke, my Lord? Ham.'
Future improvements
As with every project, there is always space to improve and here are some things which can be done with markovipy
- Specify the number of sentences to be generated when the API is being called. As of now only one sentence gets generated till the period.
- I am storing the mappings of possible words in memory as of now which can be shifted to redis
- Or if you can suggest something, I would be very happy to take a look. Create an issue here on it’s github page. https://github.com/tasdikrahman/markovipy/issues/
I would like to end this article using the last issue of Calvin and Hobbes which was on 31st December, 1995. The same year and month that I was born :)

Thanks for your time. Cheers!
DISCLAIMER: All Calvin and Hobbes Comic strips and images copyright to Bill Watterson and publishers. All written © CalvinAndHobbes.co.uk